Page Not Found
Page not found. Your pixels are in another canvas.

A list of all the posts and pages found on the site. For you robots out there is an XML version available for digesting as well.
Page not found. Your pixels are in another canvas.
About me
This is a page not in th emain menu
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Computational cold storage for data-intensive sciences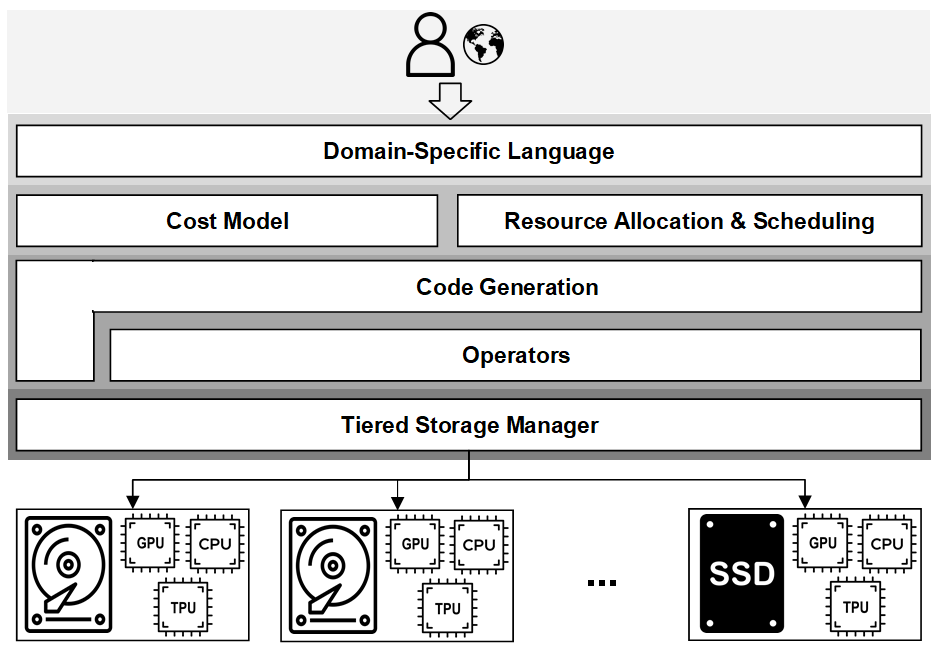
A benchmarking suite for cold data storage systems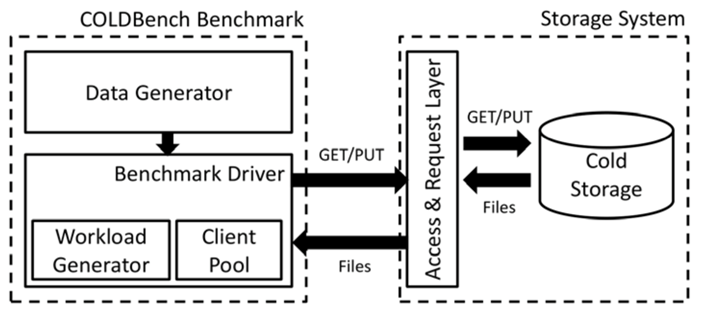

(Creative Commons BY-NC 3.0 license)
Image courtesy of NASA
Short description of portfolio item number 1
Computational cold storage for data-intensive sciences
A benchmarking suite for cold data storage systems
Short description of portfolio item number 1
Published in DBPL, 2017
Marcus Paradies (SAP), Cornelia Kinder (SAP), Jan Bross (SAP), Thomas Fischer (SAP), Romans Kasperovics (SAP), Hinnerk Gildhoff (SAP)
Abstract. Real-world graph applications are typically domain-specific and model complex business processes in the property graph data model. To implement a domain-specific graph algorithm in the context of such a graph application, simply providing a set of built-in graph algorithms is usually not sufficient nor does it allow algorithm customization to the user’s needs. To cope with these issues, graph database vendors provide—in addition to their declarative graph query languages—procedural interfaces to write user-defined graph algorithms.
Published in SPIRE, 2017
Jan Bross (KIT), Simon Gog (KIT), Matthias Hauck (SAP), Marcus Paradies (SAP)
Abstract. Several compressed graph representations were proposed in the last 15 years. Today, all these representations are highly relevant in practice since they enable to keep large-scale web and social graphs in the main memory of a single machine and consequently facilitate fast random access to nodes and edges.
Published in GRADES-NDA, 2018
Gábor Szárnyas (Budapest University of Technology and Economics), Arnau Prat-Pérez (DAMA UPC), Alex Averbuch (Neo4j), József Marton (Budapest University of Technology and Economics), Marcus Paradies (German Aerospace Center), Moritz Kaufmann (TU Munich/Tableau), Orri Erling (OpenLink Software), Peter Boncz (CWI), Vlad Haprian (Oracle Labs), János Benjamin Antal (Budapest University of Technology and Economics)
Abstract. In this short paper, we provide an early look at the LDBC Social Network Benchmark’s Business Intelligence (BI) workload which tests graph data management systems on a graph business analytics workload. Its queries involve complex aggregations and navigations (joins) that touch large data volumes, which is typical in BI workloads, yet they depend heavily on graph functionality such as connectivity tests and path finding. We outline the motivation for this new benchmark, which we derived from many interactions with the graph database industry and its users, and situate it in a scenario of social network analysis. The workload was designed by taking into account technical “chokepoints” identified by database system architects from academia and industry, which we also describe and map to the queries. We present reference implementations in openCypher, PGQL, SPARQL, and SQL, and preliminary results of SNB BI on a number of graph data management systems.
Published in SIGMOD, 2018
Renzo Angles (Universidad de Talca), Marcelo Arenas (PUC), Pablo Barcelo (Universidad de Chile), Peter Boncz (CWI), George Fletcher (Technische Universiteit Eindhoven), Claudio Gutierrez (Universidad de Chile), Tobias Lindaaker (Neo4j), Marcus Paradies (German Aerospace Center), Stefan Plantikow (Neo4j), Juan Sequeda (Capsenta), Oskar van Rest (Oracle), Hannes Voigt (TU Dresden)
Abstract. We report on a community effort between industry and academia to shape the future of graph query languages. We argue that existing graph database management systems should consider supporting a query language with two key characteristics. First, it should be composable, meaning, that graphs are the input and the output of queries. Second, the graph query language should treat paths as first-class citizens. Our result is G-CORE, a powerful graph query language design that fulfills these goals, and strikes a careful balance between path query expressivity and evaluation complexity.
Published in DATA, 2018
Frank Tetzel (SAP), Hannes Voigt (TU Dresden), Marcus Paradies (German Aerospace Center), Romans Kasperovics (SAP) and Wolfgang Lehner (TU Dresden)
Abstract. A fundamental ingredient of declarative graph query languages are regular path queries (RPQs). They provide an expressive yet compact way to match long and complex paths in a data graph by utilizing regular expressions. In this paper, we systematically explore and analyze the design space for the data structures involved in automaton-based RPQ evaluation. We consider three fundamental data structures used during RPQ processing: adjacency lists for quick neighborhood exploration, visited data structure for cycle detection, and the representation of intermediate results. We conduct an extensive experimental evaluation on realistic graph data sets and systematically investigate various alternative data structure representations and implementation variants. We show that carefully crafted data structures which exploit the access pattern of RPQs lead to reduced peak memory consumption and evaluation time.
Published in LWDA, 2018
Marcus Paradies (German Aerospace Center), Sirko Schindler (German Aerospace Center), Stephan Kiemle (German Aerospace Center), Eberhard Mikusch (German Aerospace Center)
Abstract. Earth observation (EO) has witnessed a growing interest in research and industry, as it covers a wide range of different applications, ranging from land monitoring, climate change detection, and emergency management to atmosphere monitoring, among others. Due to the sheer size and heterogeneity of the data, EO poses tremendous challenges to the payload ground segment, to receive, store, process, and preserve the data for later investigation by end users. In this paper we describe the challenges of large-scale data management based on observations from a real system employed for EO at the German Remote Sensing Data Center. We outline research opportunities, which can serve as starting points to spark new research efforts in the management of large volumes of scientific data.
Published in CIDR, 2019
Marcus Paradies (German Aerospace Center)
Published in BiDS, 2019
Sirko Schindler (German Aerospace Center), Marcus Paradies (German Aerospace Center), and Andre Twele (German Aerospace Center)
Abstract. With the rapid growth of available earth observation data and the rising demand to offer web-based data portals, there is a growing need to offer powerful search capabilities to efficiently locate the data products of interest. Many such web-based data portals have been developed with vastly different search interfaces and capabilities. Up to now, there is no general consensus within the community how such a search interface should look like nor exists a detailed analysis of the user’s search behavior when interacting with such a data portal.
Published in IPDPS, 2019
Matthias Hauck (SAP), Marcus Paradies (German Aerospace Center), Holger Fröning (University of Heidelberg)
Abstract. An important concept for indivisible updates inparallel computing are atomic operations. For most architectures,they also provide ordering guarantees, which in practice can hurtperformance. For associative and commutative updates, in thispaper we present software buffering techniques that overcomethe problem of ordering by combining multiple updates in atemporary buffer and by prefetching addresses before updatingthem. As a result, our buffering techniques reduce contentionand avoid unnecessary ordering constraints, in order to increasethe amount of memory parallelism. We evaluate our techniquesin different scenarios, including applications like histogram andgraph computations, and reason about the applicability forstandard systems and multi-socket systems.
Published in ESWC, 2019
Leila Feddoul (FSU Jena), Frank Löffler (FSU Jena), and Sirko Schindler (German Aerospace Center)
Abstract. Faceted Browsing is a wide-spread approach for exploratory search. Without requiring an in-depth knowledge of the domain, users can narrow down a resource set until it fits their need. An increasing amount of data is published either directly as Linked Data or is at least annotated using concepts from the Linked Data Cloud. This allows identifying commonalities and differences among resources beyond the comparison of mere string representations of metadata. As the size of data repositories increases, so does the range of covered domains and the number of properties that can provide the basis for a new facet. Manually predefining suitable facet collections becomes impractical. We present our initial work on automatically creating suitable facets for a semantically annotated set of resources. In particular, we address two problems arising with automatic facet generation: (1) Which facets are applicable to the current set of resources and (2) which reasonably sized subset provides the best support to users?
Published in DaMoN, 2019
Bunjamin Memishi (German Aerospace Center), Raja Appuswamy (EURECOM), and Marcus Paradies (German Aerospace Center)
Abstract. The abundance of available sensor and derived data from large scientific experiments, such as earth observation programs, radio astronomy sky surveys, and high-energy physics already exceeds the storage hardware globally fabricated per year. To that end, cold storage data archives are the—often overlooked—spearheads of modern big data analytics in scientific, data-intensive application domains. While high-performance data analytics has received much attention from the research community, the growing number of problems in designing and deploying cold storage archives has only received very little attention. In this paper, we take the first step towards bridging this gap in knowledge by presenting an analysis of four real-world cold storage archives from three different application domains. In doing so, we highlight (i) workload characteristics that differentiate these archives from traditional, performance-sensitive data analytics, (ii) design trade-offs involved in building cold storage systems for these archives, and (iii) deployment trade-offs with respect to migration to the public cloud. Based on our analysis, we discuss several other important research challenges that need to be addressed by the data management community.
Published in SEMANTiCS, 2019
Leila Feddoul (FSU Jena), Sirko Schindler (German Aerospace Center), and Frank Löffler (FSU Jena)
Abstract. With the continuous growth of the Linked Data Cloud, adequate methods to efficiently explore semantic data are increasingly required. Faceted browsing is an established technique for exploratory search. Users are given an overview of a collection’s attributes that can be used to progressively refine their filter criteria and delve into the data. However, manual facet predefinition is often inappropriate for at least three reasons: Firstly, heterogeneous and large scale knowledge graphs offer a huge number of possible facets. Choosing among them may be virtually impossible without algorithmic support. Secondly, knowledge graphs are often constantly changing, hence, predefinitions need to be redone or adapted. Finally, facets are generally applied to only a subset of resources (e.g., search query results). Thus, they have to match this subset and not the knowledge graph as a whole. Precomputing facets for each possible subset is impractical except for very small graphs. We present our approach for automatic facet generation and selection over knowledge graphs. We propose methods for (1) candidate facet generation and (2) facet ranking, based on metrics that both judge a facet in isolation as well as in relation to others. We integrate those methods in an overall system workflow that also explores indirect facets, before we present the results of an initial evaluation.
Published in DISPA, 2020
Hani Al-Sayeh (Ilmenau University of Technology, Bunjamin Memishi (German Aerospace Center), Marcus Paradies (German Aerospace Center), Kai-Uwe Sattler (Ilmenau University of Technology)
Abstract. Nowadays deployment of data-intensive systems in multi-dimensional domains is achieved with insufficient knowledge regarding the data, application internals, and infrastructure requirements. In addition, the current performance prediction frameworks focus to predict the performance of data-intensive applications on mid to large-scale infrastructures, which does not seem to be always the case. We reproduced 16 applications on a small-scale cluster, and obtained concerning results from a baseline prediction framework. Consequently, we argue that neither the previous design of the experiments, nor the prediction models are sufficiently accurate at resource-constrained cluster scenarios. Therefore, we propose MASHA, a new, black-box, sampling-based approach, that is initially lead by a new design of experiments, without relying on any historical executions. This is followed by a new performance prediction model, whose main idea is that apart from the computation, the data also needs a first citizen role. Our preliminary results are promising, by means of being able to characterize complex applications, having an average prediction accuracy of 83.31% , and with a negligible overhead cost of only 2.42%. Being framework-independent, MASHA is applicable to any data-intensive distributed system.
Published in FAST, 2021
Azat Nurgaliev (German Aerospace Center), Marcus Paradies (German Aerospace Center)
Published in TAPP, 2021
Michael A. C. Johnson (Max Planck Institute for Radio Astronomy and German Aerospace Center); Marcus Paradies (German Aerospace Center) and Marta Dembska (German Aerospace Center); Kristen Lackeos (Max Planck Institute for Radio Astronomy), Hans-Rainer Klöckner (Max Planck Institute for Radio Astronomy), and David J. Champion (Max Planck Institute for Radio Astronomy); Sirko Schindler (German Aerospace Center)
Abstract. In this decade astronomy is undergoing a paradigm shift to handle data from next generation observatories such as the Square Kilometre Array (SKA) or the Vera C. Rubin Observatory (LSST). Producing real time data streams of up to 10 TB/s and data products of the order of 600 Pbytes/year, the SKA will be the biggest civil data producing machine of the world that demands novel solutions on how these data volumes can be stored and analysed. Through the use of complex, automated pipelines the provenance of this real time data processing is key to establish confidence within the system, its final data products, and ultimately its scientific results.
Published in Arxiv, 2021
Wenjun Huang (German Aerospace Center), Marcus Paradies (German Aerospace Center)
Abstract. As the volume of data that needs to be processed continues to increase, we also see renewed interests in near-data processing in the form of computational storage, with eBPF (extended Berkeley Packet Filter) being proposed as a vehicle for computation offloading. However, discussions in this regard have so far ignored viable alternatives, and no convincing analysis has been provided. As such, we qualitatively and quantitatively evaluated eBPF against WebAssembly, a seemingly similar technology, in the context of computation offloading. This report presents our findings.
Published in CIDR, 2022
Patrick Damme (Graz University of Technology & Know-Center GmbH)*; Marius Birkenbach (KAI); Constantinos Bitsakos (NTUA); Matthias Boehm (Graz University of Technology); Philippe Bonnet (IT Univ Copenhagen, Denmark); Florina M. Ciorba (Technical University of Dresden, Germany / University of Basel, Switzerland); Mark Dokter (Know-Center GmbH); Pawel Dowgiallo (Intel); Ahmed Eleliemy (University of Basel); Christian Faerber (Intel Corporation); Georgios Goumas (National Technical University of Athens); Dirk Habich (TU Dresden); Niclas Hedam (IT University of Copenhagen); Marlies Hofer (AVL List GmbH); Wenjun Huang (German Aerospace Center); Kevin Innerebner (Graz University of Technology); Vasileios Karakostas (National Technical University of Athens (NTUA)); Roman Kern (KNOW-CENTER GmbH); Tomaž Kosar (University of Maribor); Alexander Krause (TU Dresden); Daniel Krems (AVL List GmbH); Andreas Laber (Infineon); Wolfgang Lehner (TU Dresden); Eric Mier (TU Dresden); Marcus Paradies (German Aerospace Center); Bernhard Peischl (); Gabrielle Poerwawinata (University of Basel); Stratos Psomadakis (ICCS/NTUA); Tilmann Rabl (HPI, University of Potsdam); Piotr Ratuszniak (Intel Technology Poland); Pedro Silva (HPI, University of Potsdam); Nikolai Skuppin (German Aerospace Center (DLR)); Andreas Starzacher (Infineon); Benjamin Steinwender (KAI GmbH); Ilin Tolovski (Hasso Plattner Institute); Pinar Tozun (IT University of Copenhagen); Wojciech Ulatowski (Intel); Yuanyuan Wang (Technical University of Munich (TUM); German Aerospace Center (DLR)); Izajasz Wrosz (Intel); Aleš Zamuda (University of Maribor); Ce Zhang (ETH); Xiaoxiang Zhu (Technical University of Munich (TUM); German Aerospace Center (DLR)
Abstract. Integrated data analysis (IDA) pipelines—that combine data management (DM) and query processing, high-performance computing (HPC), and machine learning (ML) training and scoring—become increasingly common in practice. Interestingly, systems of these areas share many compilation and runtime techniques, and the used—increasingly heterogeneous—hardware infrastructure converges as well. Yet, the programming paradigms, cluster resource management, data formats and representations, as well as execution strategies differ substantially. DAPHNE is an open and extensible system infrastructure for such IDA pipelines, including language abstractions, compilation and runtime techniques, multi-level scheduling, hardware (HW) accelerators, and computational storage for increasing productivity and eliminating unnecessary overheads. In this paper, we make a case for IDA pipelines, describe the overall DAPHNE system architecture, its key components, and the design of a vectorized execution engine for computational storage, HW accelerators, as well as local and distributed operations. Preliminary experiments that compare DAPHNE with MonetDB, Pandas, DuckDB, and TensorFlow show promising results.
Published in SIGMOD, 2022
Hani Al-Sayeh (TU Ilmenau), Bunjamin Memishi (German Aerospace Center), Muhammad Attahir Jibril (TU Ilmenau), Marcus Paradies (German Aerospace Center), Kai-Uwe Sattler (TU Ilmenau)
Abstract. Distributed in-memory processing frameworks accelerate iterative workloads by caching suitable datasets in memory rather than recomputing them in each iteration. Selecting appropriate datasets to cache as well as allocating a suitable cluster configuration for caching these datasets play a crucial role in achieving optimal performance. In practice, both are tedious, time-consuming tasks and are often neglected by end users, who are typically not aware of workload semantics, sizes of intermediate data, and cluster specification.
Published in BTW, 2023
Joshua Reibert (German Aerospace Center), Arne Osterthun (German Aerospace Center), Marcus Paradies (German Aerospace Center)
Abstract. Spatio-temporal models of ionospheric data are important for atmospheric research and the evaluation of their impact on satellite communications. However, researchers lack tools to visually and interactively analyze these rapidly growing multi-dimensional datasets that cannot be entirely loaded into main memory. Existing tools for large-scale multi-dimensional scientific data visualization and exploration rely on slow, file-based data management support and simplistic client-server interaction that fetches all data to the client side for rendering.
In this paper we present our data management and interactive data exploration and visualization system MEDUSE. We demonstrate the initial implementation of the interactive data exploration and visualization component that enables domain scientists to visualize and interactively explore multi-dimensional ionospheric data. Use-case-specific visualizations additionally allow the analysis of such data along satellite trajectories to accommodate domain-specific analyses of the impact on data collected by satellites such as for GNSS and earth observation.
Published:
This is a description of your talk, which is a markdown files that can be all markdown-ified like any other post. Yay markdown!
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
Undergraduate course, Friedrich-Schiller University Jena, 2021
This course is primarily designed for undergraduate students, who already completed introductionary courses in database & distributed systems, algorithms & data structures, and operating systems. The course puts a strong emphasis on a systemic view of data storage systems, ranging from the physical inner workings of modern data storage devices, such as HDDs and SSDs, to full-fledged, distributed, cloud-based exascale storage systems. The students will gradually gain a deeper understanding of fundamental concepts and algorithms of data storage systems, including replication & crash recovery, data deduplication, and storage tiering & caching, but also insights into systematic I/O performance analysis & tuning on the device and the file system level. In the second half of the course, the fundamental concepts of file systems and large-scale distributed storage systems will be discussed. Finally, we conclude the course with an outlook into active areas of research and novel storage technologies that will come up (or are already on the market) and will have a quite dramatic impact on any data-intensive application having to deal with large data volumes.
Undergraduate course, Friedrich-Schiller University Jena, 2021
Undergraduate course, Ilmenau University of Technology, 2022
This course is primarily designed for undergraduate students, who already completed introductionary courses in database & distributed systems, algorithms & data structures, and operating systems. The course puts a strong emphasis on a systemic view of data storage systems, ranging from the physical inner workings of modern data storage devices, such as HDDs and SSDs, to full-fledged, distributed, cloud-based exascale storage systems. The students will gradually gain a deeper understanding of fundamental concepts and algorithms of data storage systems, including replication & crash recovery, data deduplication, and storage tiering & caching, but also insights into systematic I/O performance analysis & tuning on the device and the file system level. In the second half of the course, the fundamental concepts of file systems and large-scale distributed storage systems will be discussed. Finally, we conclude the course with an outlook into active areas of research and novel storage technologies that will come up (or are already on the market) and will have a quite dramatic impact on any data-intensive application having to deal with large data volumes.
Undergraduate course, Ilmenau University of Technology, 2023
This course is primarily designed for undergraduate students, who already completed introductionary courses in database & distributed systems, algorithms & data structures, and operating systems. The course puts a strong emphasis on a systemic view of data storage systems, ranging from the physical inner workings of modern data storage devices, such as HDDs and SSDs, to full-fledged, distributed, cloud-based exascale storage systems. The students will gradually gain a deeper understanding of fundamental concepts and algorithms of data storage systems, including replication & crash recovery, data deduplication, and storage tiering & caching, but also insights into systematic I/O performance analysis & tuning on the device and the file system level. In the second half of the course, the fundamental concepts of file systems and large-scale distributed storage systems will be discussed. Finally, we conclude the course with an outlook into active areas of research and novel storage technologies that will come up (or are already on the market) and will have a quite dramatic impact on any data-intensive application having to deal with large data volumes.